Abstract
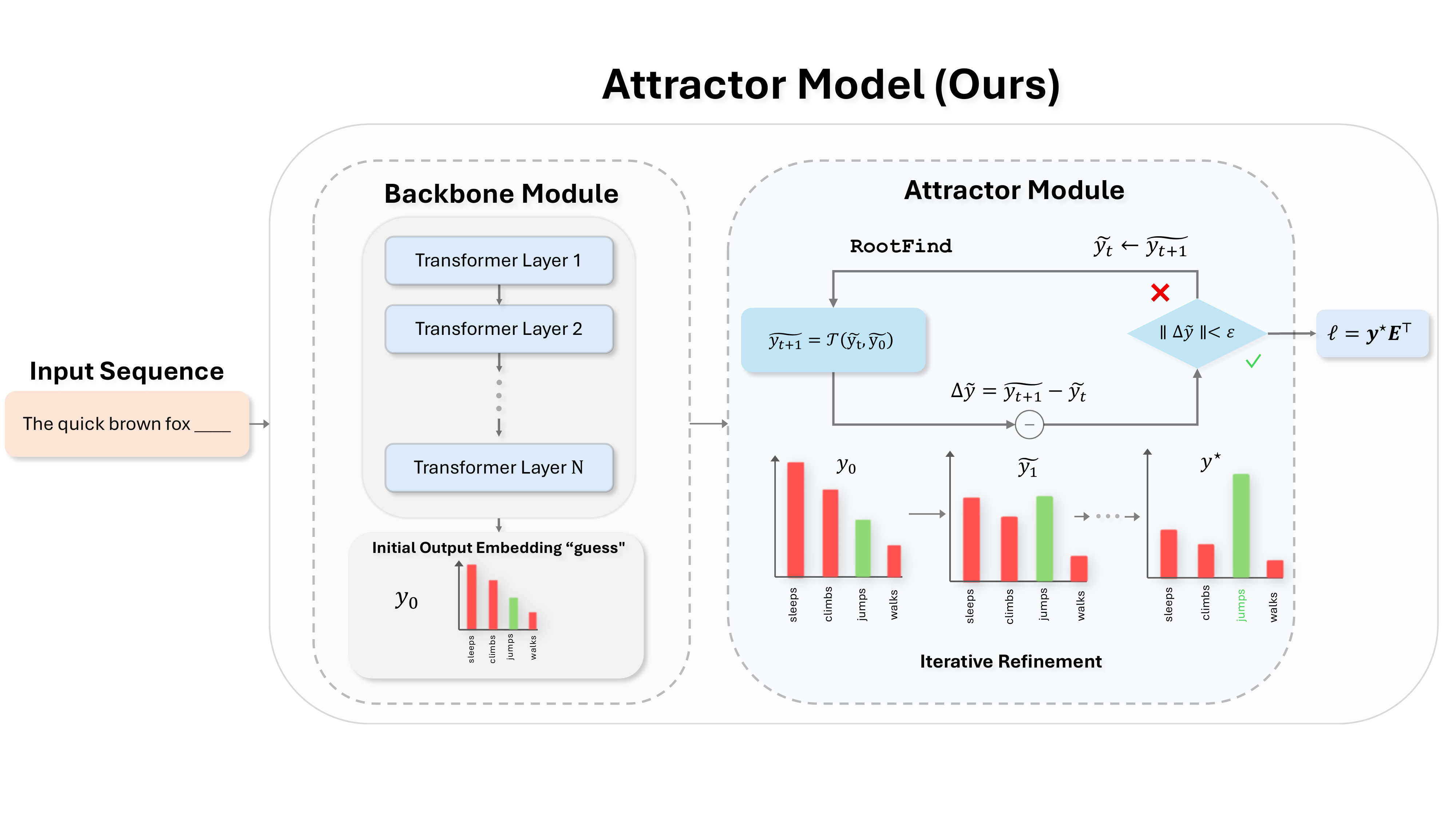
Looped Transformers offer a promising alternative to purely feed-forward computation by iteratively refining latent representations, improving language modeling and reasoning. Yet recurrent architectures remain unstable to train, costly to optimize and deploy, and constrained to small, fixed recurrence depths. We introduce Attractor Models, in which a backbone module first proposes output embeddings, then an attractor module refines them by solving for the fixed point, with gradients obtained through implicit differentiation. Thus, training memory remains constant in effective depth, and iterations are chosen adaptively by convergence.
Empirically, Attractor Models outperform existing models across two regimes, large-scale language-model pretraining and reasoning with tiny models. In language modeling, Attractor Models deliver a Pareto improvement over standard Transformers and stable looped models across sizes, improving perplexity by up to 46.6% and downstream accuracy by up to 19.7% while reducing training cost. Notably, a 770M Attractor Model outperforms a 1.3B Transformer trained on twice as many tokens. On challenging reasoning tasks, we show that our model with only 27M parameters and approximately 1000 examples achieves 91.4% accuracy on Sudoku-Extreme and 93.1% on Maze-Hard, scaling favorably where frontier models like Claude and GPT o3 fail completely, and specialized recursive reasoners collapse at larger sizes. Lastly, we show that Attractor Models exhibit a novel phenomenon, which we call equilibrium internalization: fixed-point training places the model's initial output embedding near equilibrium, allowing the solver to be removed at inference time with little degradation.
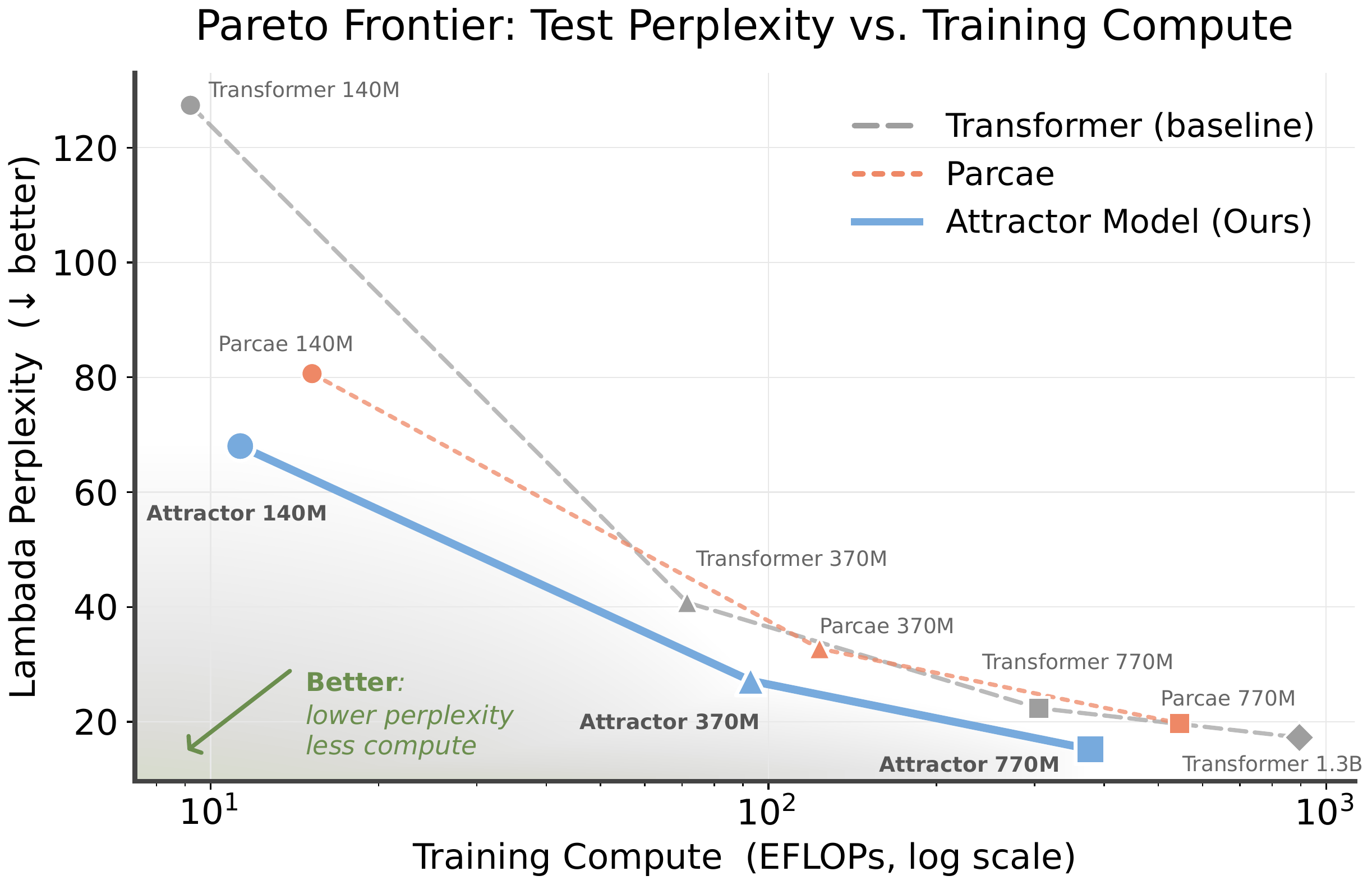
Pareto frontier: Lambada perplexity vs. training FLOPs. Attractor Models achieve strong language-modeling performance with less compute across all sizes.
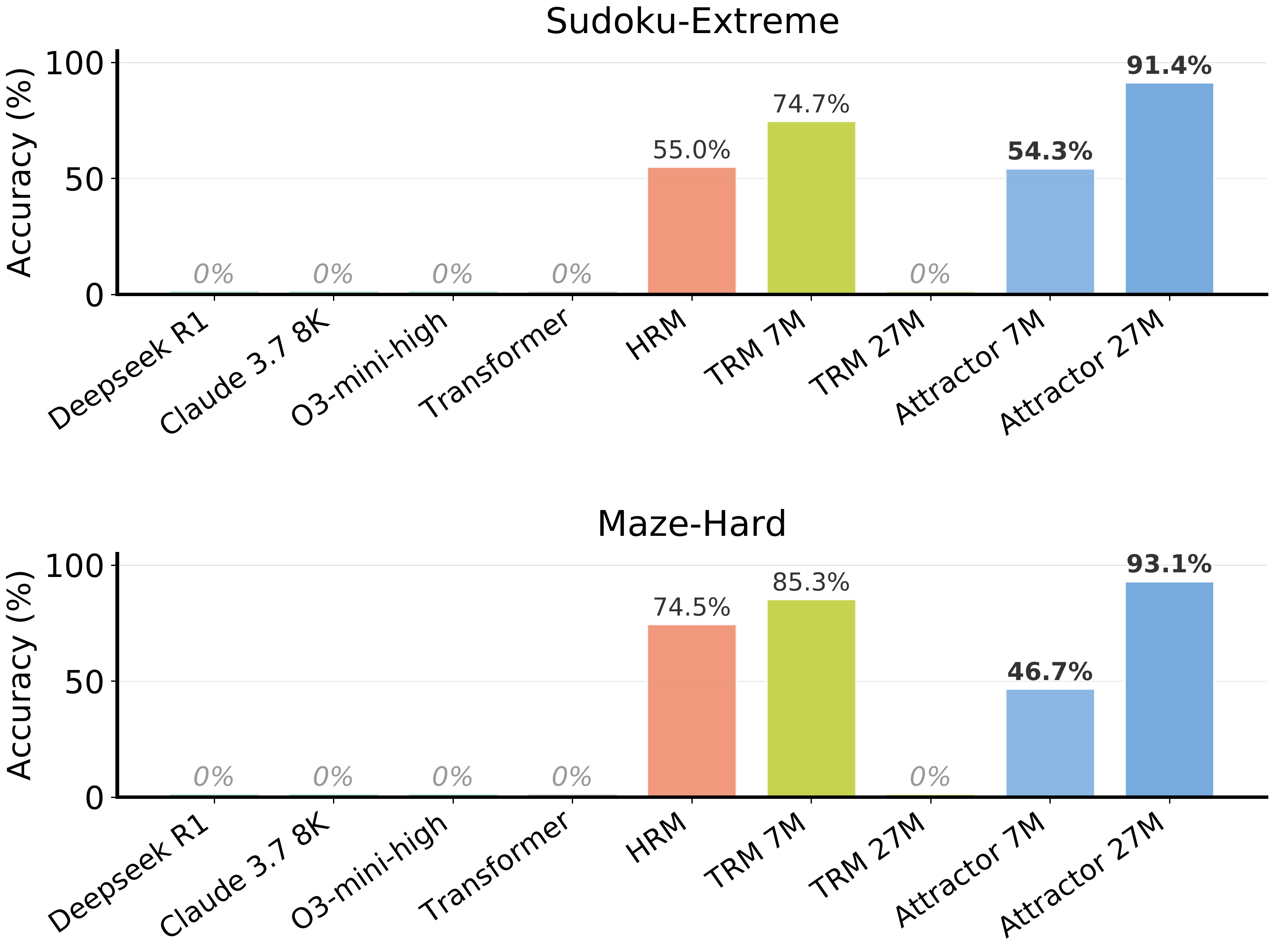
Hard reasoning tasks. Attractor Models (27M params) achieve 91.4% on Sudoku-Extreme and 93.1% on Maze-Hard, where frontier models score 0%.
Equilibrium internalization: as training progresses, the backbone's proposal approaches the fixed point, requiring fewer solver iterations at inference.
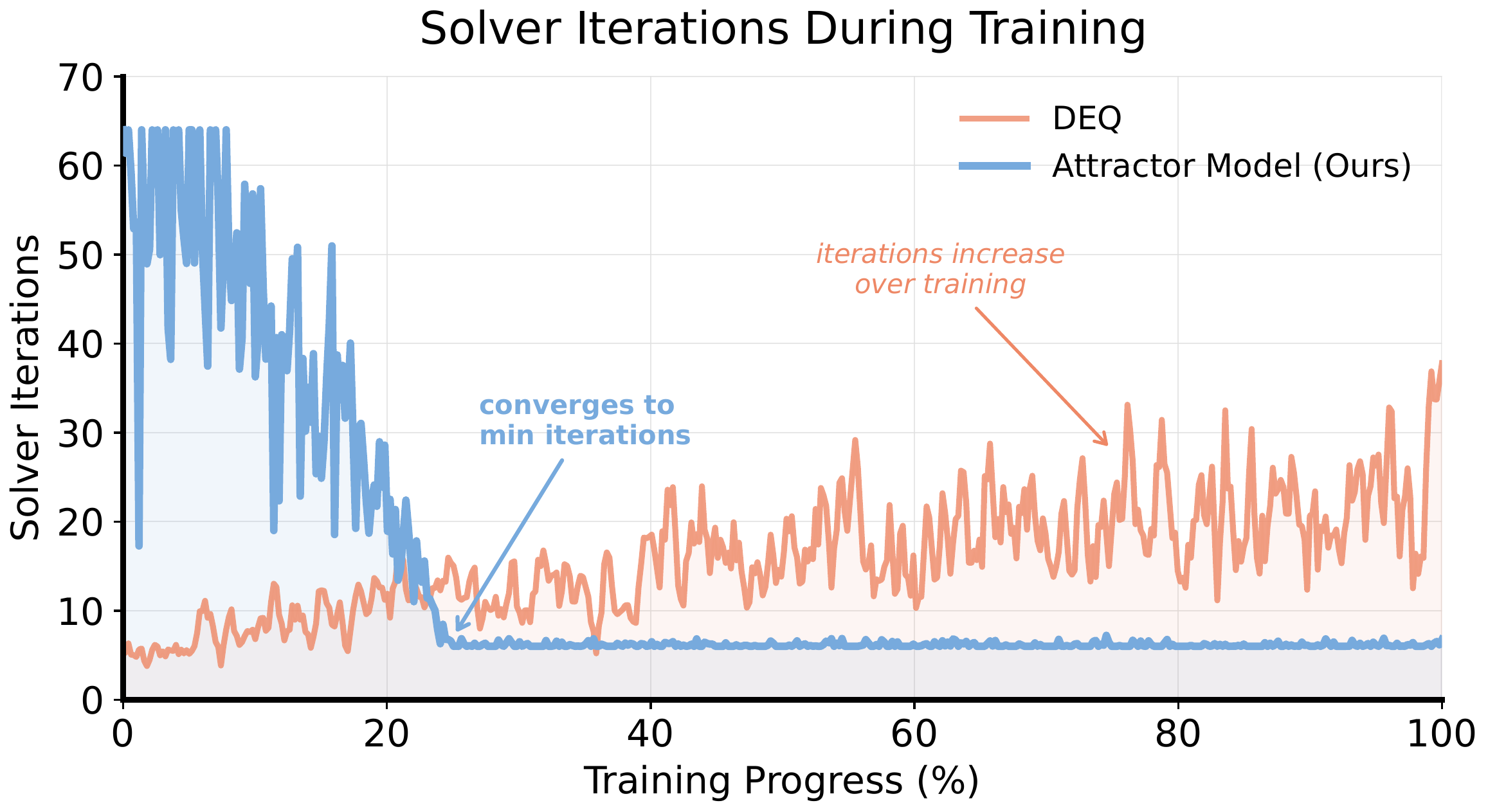
Solver iterations during training. DEQ requires increasingly many iterations, whereas Attractor Models rapidly settle to the minimum iteration count.
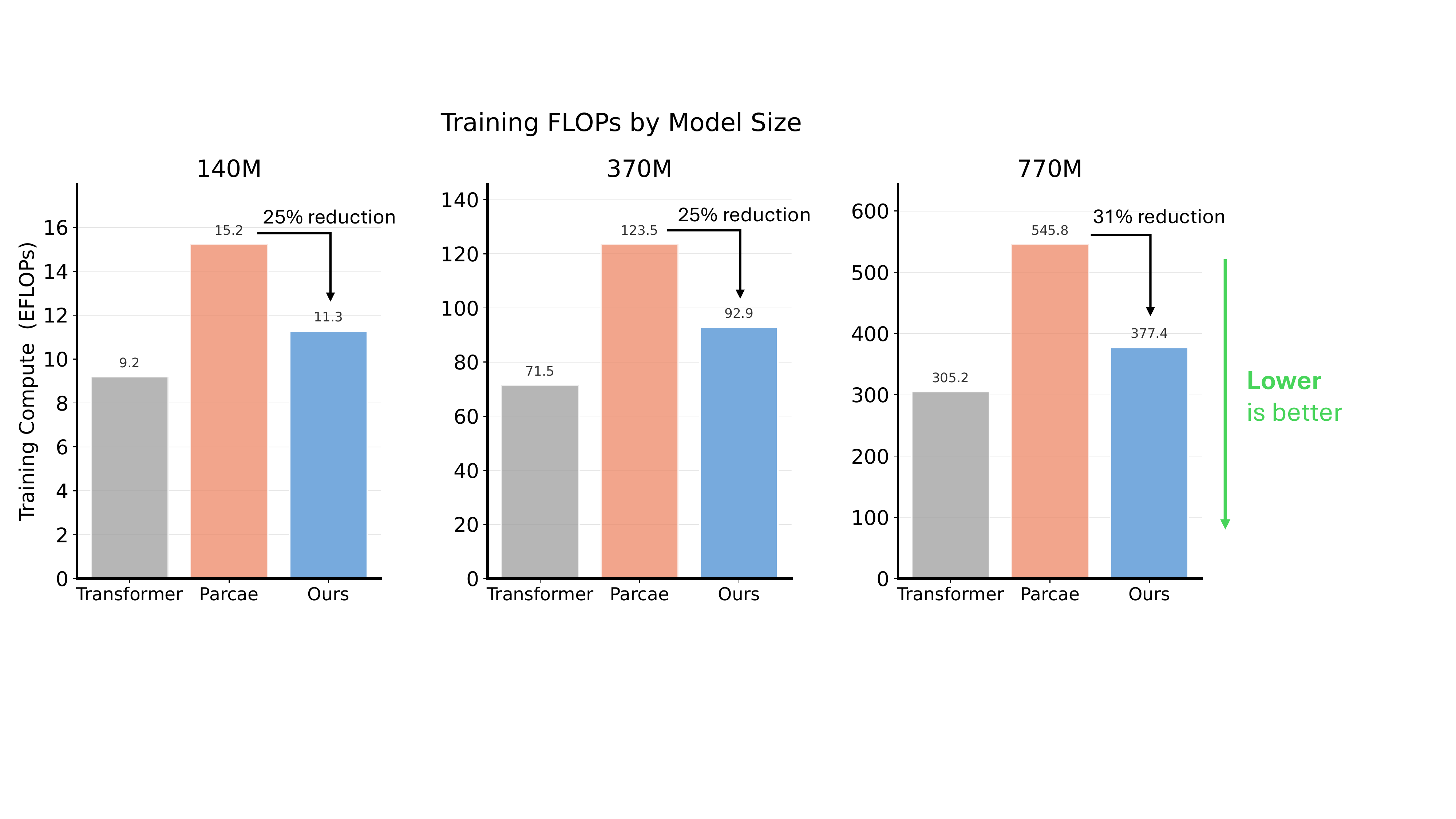
Training efficiency: Attractor Models use 25–31% fewer FLOPs than Parcae because the solver converges before T_max and the backward pass uses the one-step approximation.
Language Modeling Results
We compare Attractor Models against parameter-matched Transformers and Parcae (a looped LM) at three scales. Our 770M model performs comparably to a standard Transformer with nearly double its size and tokens trained on.
| Size | Model | Val. PPL ↓ | Lambada PPL ↓ | Core ↑ | Core-Ext. ↑ |
|---|---|---|---|---|---|
| 140M | Transformer | 21.48 | 127.39 | 13.00 | 8.80 |
| Parcae | 19.06 | 80.64 | 14.04 | 9.67 | |
| Attractor Model | 18.30 | 68.02 | 14.59 | 10.03 | |
| 370M | Transformer | 15.79 | 40.77 | 17.46 | 11.71 |
| Parcae | 14.49 | 32.74 | 20.00 | 12.75 | |
| Attractor Model | 14.03 | 27.14 | 20.24 | 12.64 | |
| 770M | Transformer | 13.08 | 22.37 | 22.42 | 14.20 |
| Parcae | 12.49 | 19.71 | 25.07 | 15.19 | |
| Attractor Model | 12.09 | 15.21 | 26.83 | 15.42 | |
| 1.3B | Transformer | 11.95 | 17.26 | 25.45 | 15.90 |
Reasoning Results
On challenging reasoning benchmarks (Sudoku-Extreme and Maze-Hard), Attractor Models with only 27M parameters and ~1000 training examples dramatically outperform frontier LLMs and specialized recursive architectures.
| Method | # Params | Sudoku-Extreme ↑ | Maze-Hard ↑ |
|---|---|---|---|
| DeepSeek R1 | 671B | 0.0% | 0.0% |
| Claude 3.7 | ? | 0.0% | 0.0% |
| O3-mini-high | ? | 0.0% | 0.0% |
| Transformer | 27M | 0.0% | 0.0% |
| HRM | 27M | 55.0% | 74.5% |
| TRM | 7M | 74.7% | 85.3% |
| TRM | 27M | 0.0% | 0.0% |
| Attractor Model (Ours) | 7M | 54.3% | 46.7% |
| Attractor Model (Ours) | 27M | 91.4% | 93.1% |
BibTeX
@misc{feinashley2026solveloopattractormodels,
title={Solve the Loop: Attractor Models for Language and Reasoning},
author={Jacob Fein-Ashley and Paria Rashidinejad},
year={2026},
eprint={2605.12466},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.12466},
}